




I Have Too Much Data!
The biggest challenge organizations face when incorporating AI technology is the disorganization of information and the sometimes uncontrollable volume of data.
Implementing intelligent solutions without having refined data only worsens the situation. These solutions won’t “tidy up the house” on their own but will merely automate the chaos. Avoiding this is one of the principles of methodologies like ITIL, which emphasize the need to optimize processes before automating them. Otherwise, inefficiencies and defects will not only persist but will gradually fall out of control, and no one will remember they’re still there, hindering optimal results and, even worse, doing so automatically.

Just like any construction, technological solutions (particularly automation through intelligent agents) require a solid foundation to generate benefits in the short (operational), medium (tactical), and long term (strategic).
The first step is to understand what data actually is. Data is nothing more than digital events that, when processed, make sense in the form of information. It’s from this information that we begin to make decisions; data must be clean and organized for the generated information to be useful.
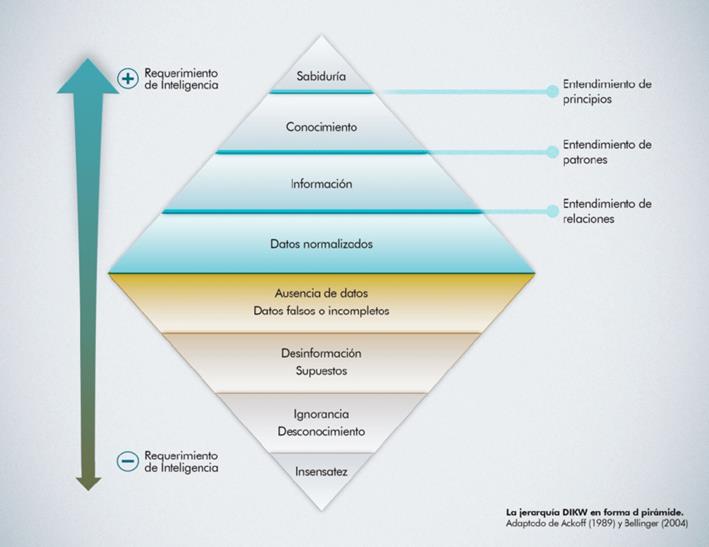
But what is useful information, and how do I segregate it from all the information I handle? As a rule, we can establish that useful information is that which is related to business drivers. That is, information necessary for productive processes and decision-making within each organization’s business model. Any other information will only introduce “noise” to intelligent systems and pattern searches, potentially leading to poor decisions.

This is a reality that increasingly impacts organizations of all types. We can even find examples in high-performance sports, like Formula 1. Each of these cars has 300 sensors that send 1,000,000 (yes, one million) data points per second to real-time telemetry programs.

With two cars on the track, each team receives 2 million data points per second, analyzed in real time by intelligent systems that provide teams with predictions about machine behavior. Decisions in the pit are assisted by these systems, allowing teams to save milliseconds and maximize the use of cars and the capabilities of each driver in pursuit of victory. Winning or losing the race depends on the interpretation and prediction that the systems can make based on the data.
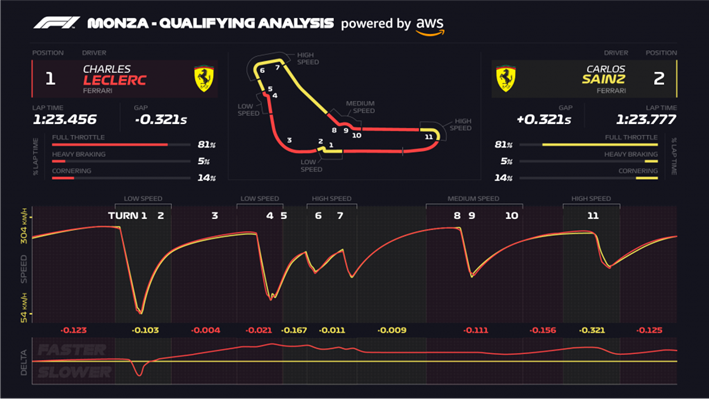
If even a portion of those millions of data points were not relevant, it would be impossible to achieve the precision required in the predictions that this “business” demands. Otherwise, the decisions could lead to the team’s failure.

Ultimately, organizations have a path to follow in incorporating the latest technology to enable and facilitate the path to operational excellence, cost reduction, and high scalability in processes (and consequently in the organizations). To achieve this, they need to understand data, identify it, organize it, and maintain it so that it can be consumed safely and optimally.
Today, there are academic disciplines that help us acquire the necessary knowledge to support organizations in this great challenge. It’s worth looking at these opportunities since we are not facing a challenge of the future but a need of today.